爬虫的分类
通用爬虫
定义:又称全网爬虫,爬行对象从种子URL扩充到整个WEB,主要为搜索引擎和大型web服务提供商采集数据,一般用于搜索引擎系统的数据采集模块。
优势:开放性 速度快
缺点:目标不明确 返回内容包含大量用户不需要的东西
聚焦爬虫
定义:又称主题网络爬虫,是指选择性的爬取那些预定好的主题相关页面的爬虫。
优势:目标明确 对用户的需要明确 返回内容固定
爬虫robots协议
定义
robots协议是一种用于限制爬虫爬取路径的一个规则文件,用于告知搜索引擎哪些网页可以被抓取,哪些页面不能被抓取。一般存放在网站根目录下,以robots.txt命名。
值得注意的是:聚焦爬虫不遵守robots
文件写法
1 | User-agent: 爬虫身份,如google网页搜索爬虫为Googlebot。*代表所有爬虫 |
示例:
1 | User-agent: * |
使用
爬取流程
一个简单的爬取baidu.com的示例如下:
1 | import urllib.request |
运行后的html文件打开如下:
HTTP请求
七个步骤
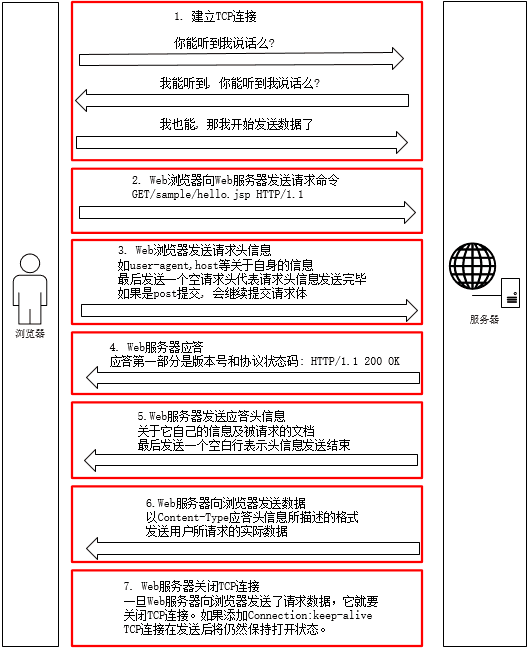
- 建立TCP连接 即三次握手
- 浏览器发送请求(Request)
- 浏览器发送请求头(request header)
- 服务器发送响应(Response)
- 服务器发送响应头(response header)
- 服务器发送数据
- 服务器关闭连接 即四次挥手
请求头
请求头描述了客户端向服务器发送请求时使用的http协议类型,所使用的编码,以及发送内容的长度,refer,等等。refer干嘛的,一般用来做简单的防跨站攻击。
一些常用的参数及含义如下:
| 参数 | 示例 | 解释 |
|---|---|---|
| Accept | text/plain, text/html,application/json | 客户端能够接收的内容类型 |
| Cookie | - | 一般是用户标识 |
| User-Agent | Mozilla/5.0 (Linux; X11) | 发送请求的用户浏览器信息 |
| Accept-Charset | iso-8859-5 ;utf-8 | 可以接受的字符编码集 |
| Accept-Language | en,zh | 可接受的语言 |
响应头
响应头用来描述服务器回给你对所返回的content的一些一些描述,我是什么服务器,我返回的是啥编码,我返回的内容有多长等等。
一些常用的参数及含义如下:
| 参数 | 示例 | 解释 |
|---|---|---|
| Content-Type | text/html; charset=utf-8 | 返回内容的MIME类型 |
| Date | Mon, 03 May 2021 02:11:53 GMT | 日期 |
爬虫设置请求头
以urllib.request库为例
1 | import urllib.request |
IP代理
IP分类
透明:对方知道我们的真实IP
匿名:对方不知道我们的真实IP,只知道我们用了代理
高匿:对方即不知道我们的真实IP,也不知道我们用了代理
关于Python爬虫设置IP池代理可以查看我的这篇博客
数据解析
通过Python爬虫获取到页面信息后,我们需要将数据进行解析,获取到其中我们需要的信息。通常有以下几种方式:
正则表达式
正则表达式是用来解析字符串的一个工具,应用广泛。在JS、Java、Python中都可以看见它的身影。
Xpath
Xpath是一门在XML或HTML文档中查找信息的语言。使用Xpath一般需要先把内容转换成XML格式的文档。其获取到的结果为列表。一般流程如下:
1 | from lxml import etree |
运行结果如下:
1 | ['first item', 'second item', 'third item', 'fourth item', 'fifth item'] |
此处只简单介绍一下Xpath,更多用法还得参见其他博客。
BeautifulSoup4
Beautiful Soup 是一个可以从DOM文件(HTML或XML)中提取数据的Python库,和Xpath的作用类似,有官方中文文档
关于BeautifulSoup4的介绍可以看我的这篇博客